Large Language Models (LLMs) have taken the enterprise world by storm, but their inherent limitations—namely hallucination, static training cutoff dates, and lack of access to private internal data—remain major roadblocks to adoption. Retrieval-Augmented Generation (RAG) has emerged as the architectural solution of choice to bridge this gap.
1. The Core Limitation of Fine-Tuning
Initially, many developers assumed that fine-tuning models on proprietary corporate data was the best way to inject private knowledge. However, fine-tuning is extremely expensive, requires constant computational resource allocations, and fails to prevent models from hallucinating false facts when queried on edge cases. More importantly, fine-tuned models are static; they cannot adapt in real-time as your database updates.
2. Enter Retrieval-Augmented Generation (RAG)
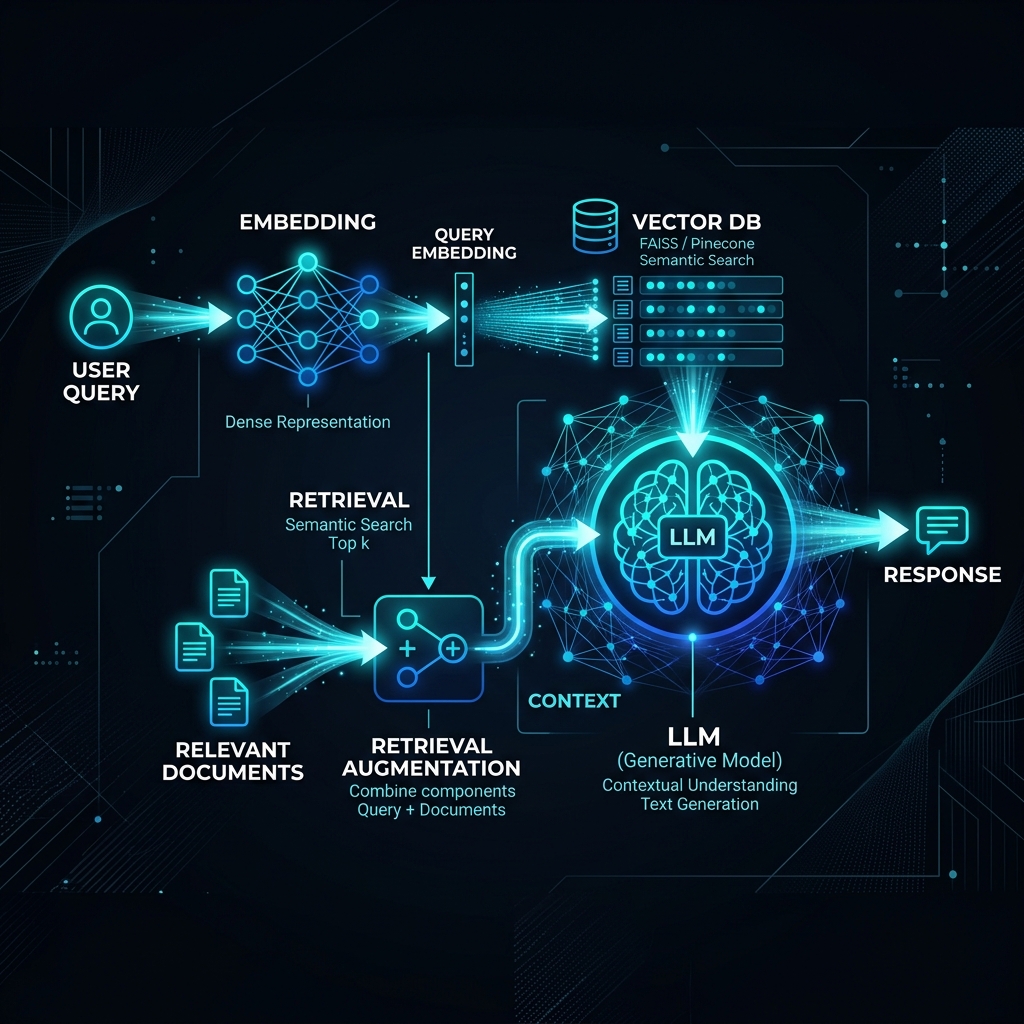
Instead of trying to bake knowledge directly into the weights of the model, RAG treats the LLM as an open-book reader. When a user submits a query:
- The system converts the query into a high-dimensional vector representation (embedding).
- A vector database indexes and retrieves the most semantically relevant document chunks from your company's private files.
- The system appends these retrieved document snippets directly into the model's context window.
- The LLM synthesizes an accurate answer based solely on the provided reference documents, citing sources.
3. Key Architectural Components
To implement a production-ready RAG pipeline, enterprises rely on a standardized stack:
- Embeddings Model: Converts raw text files into vectors (e.g., OpenAI text-embedding-3 or Cohere Embed).
- Vector Database: Stores and queries high-dimensional vectors with sub-millisecond latencies (e.g., Pinecone, Milvus, Qdrant).
- Orchestration Framework: Coordinates query ingestion, vector lookups, prompt building, and LLM queries (e.g., LangChain, LlamaIndex).
4. Enterprise Benefits of RAG
RAG provides substantial operational advantages over fine-tuning:
- Real-Time Updates: As soon as a document is added or modified in your knowledge base, the vector index updates, making the information queryable immediately.
- Granular Data Access Controls: Document access tokens can be verified during vector retrieval, ensuring that users only receive answers generated from sources they are permitted to view.
- Reduced Hallucination Rate: By strictly instructing the model to rely only on the retrieved reference chunks, hallucinations are almost completely eliminated, ensuring enterprise-grade reliability.
Conclusion
RAG has turned LLMs from generic conversational chatbots into reliable corporate search engines. For any enterprise seeking to securely query manuals, codebases, or CRM histories, RAG represents the gold standard of modern AI architecture.